
Lesson 6: 隨機亂數與相關圖形(Random numbers and the associated graphs)
Objective:
- 學習自幾個著名的離散型與連續型分配產生隨機亂數。
- 學習不同的亂數產生方式。
- 隨機亂數的視覺化表現,譬如直方圖(Histogram)、盒鬚圖(Boxplot)、機率圖(Probability Plot)與經驗 CDF 圖(Empirical CDF)。
Prerequisite:
- 懂得機率分配的意義與分配圖形的繪製(PDF, CDF)。
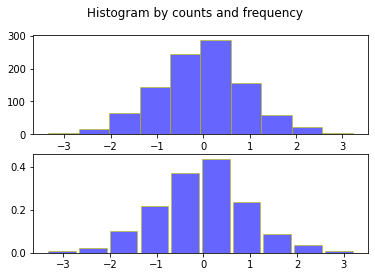
範例 1:直方圖 Histogram
從常態分配 
注意事項:
本範例呈現兩種生成亂數的方式: numpy method 及 scipy function。
了解 “seed number” 扮演的角色。
直方圖的做法有二: by counts or by frequency(如圖).
繪製直方圖要特別留意樣本數造成的影響。另一個影響因素是 bin numbers(組距數)。針對相同樣本數(特別是中等數量,譬如 100, 200),試試不同的 bin 數量所造成的視覺變化。
import numpy as np
from scipy.stats import norm
import matplotlib.pyplot as plt
# random number generator with random seed
rng = np.random.default_rng() # (seed=...)
x = rng.normal(loc = 0, scale = 1, size = 1000)
# x = norm.rvs(loc = 0, scale = 1, size = 1000)
fig, (ax1, ax2) = plt.subplots(2, 1)
# typical histogram by counts
ax1.hist(x, bins = 10, alpha = 0.6, color = 'b', edgecolor = 'y', linewidth = 1)
# histogram by frequency
ax2.hist(x, bins = 10, alpha = 0.6, color = 'b', edgecolor = 'y', linewidth = 1, density = True, rwidth = 0.9)
plt.suptitle('Histogram by counts and frequency')
plt.show()
範例 2:盒鬚圖 Boxplot
繪製兩組不同資料的盒鬚圖, 分別來自 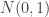

注意事項:
示範使用與不使用 random seed 來產生亂數之不同。當使用固定的 random seed 時,是否會產生一樣的亂數?試著印出來看看。有些使用者習慣使用固定的 random seed,卻不知每次都產生相同的亂數,造成後續的計算得到相同的結果。
繪製盒鬚圖的技巧非常豐富,本範例僅提供一二,譬如, 使用了 dictionary “boxprops” and “flierprops”。
import numpy as np
from scipy.stats import norm
import matplotlib.pyplot as plt
rng = np.random.default_rng(0) # seed is fixed
n = 1000 # sampe size
x1 = norm.rvs(size = n, random_state = rng) # standard normal
x2 = norm.rvs(loc = 1, scale = 2, size = n)
# run a few times and check the random numbers generated
# with and without fixing the random seed.
# print(x1[0:3])
# print(x2[0:3])
fig, (ax1, ax2) = plt.subplots(1, 2, figsize = (9, 6))
ax1.boxplot(np.c_[x1, x2], notch = True, vert = True, labels = ['X1','X2'])
# plt.show()
# use boxplot properties
boxprops = dict(linestyle = '--', linewidth = 3, color = 'darkgoldenrod')
flierprops = dict(marker='o', markerfacecolor = 'green',
markersize = 8, linestyle = 'none') # define outliers
labels = ['N(0,1)','N(1,1)']
ax2.boxplot(np.c_[x1, x2], boxprops = boxprops,
flierprops = flierprops, labels = labels)
plt.show()
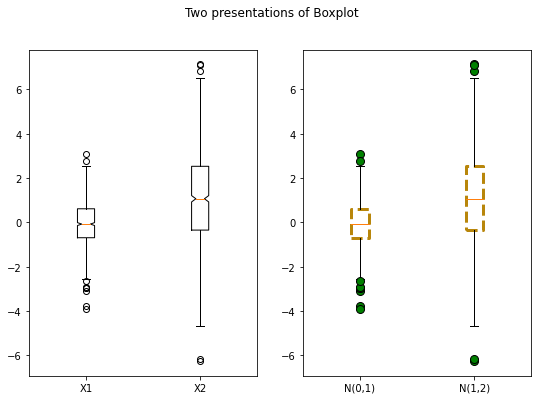
範例 3:常態機率圖 Normal Probability plot
各別繪製兩組資料的常態機率圖,其中一組資料來自常態分配,另一組來自右偏的 
注意事項:
本範例程式刻意採用 numpy 的方式產生隨機樣本。
機率圖(probability plot)可以設定為各種分配。當設定為常態分配時,可以用來測試該樣本是否來自常態。
當機率分配設定為常態以外的分配時,必須額外指定 “sparams” 作為該分配的參數。下列程式碼註解的部分設定了卡方分配(自由度為 2)。
import numpy as np
import scipy.stats as stats
x1 = np.random.normal(loc = 2, scale = 5, size=100)
x2 = np.random.chisquare(df = 2, size = 100)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize = (12, 4))
stats.probplot(x1, dist = "norm", plot = ax1)
stats.probplot(x2, dist = "norm", plot = ax2)
# stats.probplot(x2, dist = "chi2", sparams = 2, plot = ax2)
ax1.set_title('Data from Normal')
ax2.set_title('Data from $\chi^2$')
plt.suptitle('probability Plot')
plt.show()
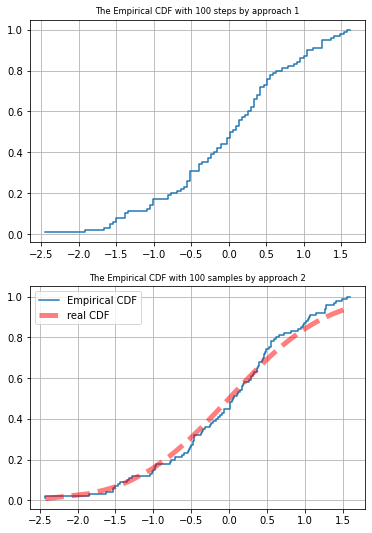
範例 4:經驗累積密度函數 Empirical CDF (ECDF)
繪製一組來自常態分配 
注意事項:
ECDF 圖來自樣本數為 n 的樣本,當 n 愈大時,與真實 CDF 愈接近。因此 ECDF 為真實 CDF 的模擬版本。
scipy 模組提供了 “cumfreq” (cumulative frequency over sorted sample) 做為 ECDF。 如下列程式碼之 Approach 1。
模擬 CDF 最簡單的方式就是將每個樣本點的發生機率設為一樣,即
. 如下列程式碼之 Approach 2。
將 ECDF 與真實 CDF 畫在一起, 並觀察樣本數的影響。
import numpy as np
from scipy.stats import norm
from scipy.stats import cumfreq # for ECDF
n = 100
sample = norm.rvs(size = n)
# Approach 1
num_bins = n # cumulative frequency over each sample
res = cumfreq(sample, num_bins)
# print(res.lowerlimit, res.binsize, res.cumcount.size)
x = res.lowerlimit + np.linspace(0,
res.binsize * res.cumcount.size, res.cumcount.size)
fig, (ax1, ax2) = plt.subplots(2, 1, figsize = (6, 9))
# ax1.bar(x, res.cumcount/n, width=res.binsize)
ax1.plot(x, res.cumcount/n, drawstyle = 'steps-pre')
ax1.set_title('The Empirical CDF with {} steps'.format(num_bins), fontsize = 'small')
ax1.grid(True)
# Approach 2
x = np.sort(sample)
Y = np.arange(1, n+1) / n
ax2.plot(x, Y, drawstyle = 'steps-pre', label = 'Empirical CDF')
# draw the theoretical CDF of Z
Y_ = norm.cdf(x)
ax2.plot(x, Y_, color = 'r', linestyle = '--',
linewidth = 5, alpha = 0.5, label = 'real CDF')
ax2.legend(), plt.grid(True)
ax2.set_title('The Empirical CDF with {} samples'.format(num_bins), fontsize = 'small')
plt.show()
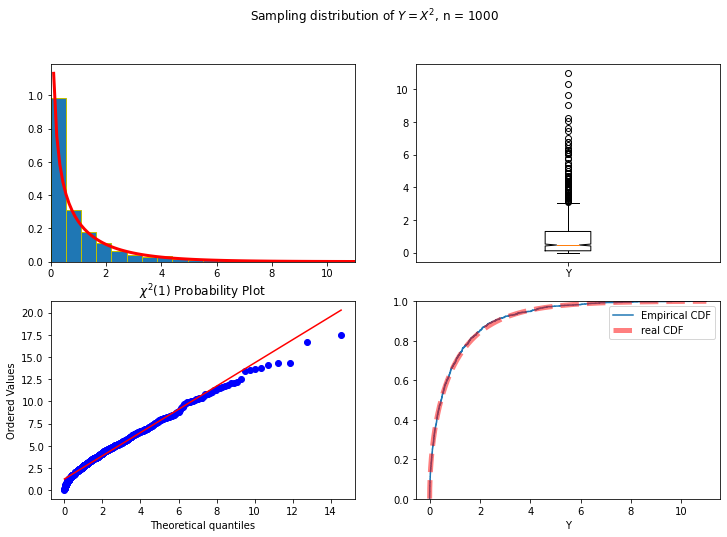
練習:抽樣分配 Sampling Distribution
假設隨機變數 

從常態分配
繪製直方圖(貼上真實的
的 PDF 圖)如下圖左上。
繪製 Boxplot, Probability plot 與 ECDF(貼上真實的 CDF 圖),如下圖,作為佐證,尤其是 ECDF 圖與真實 CDF 之相似度,隨樣本數增加而更像。
可以將 ECDF 的計算寫成一個函數,如 ecdf(sample): …. return x, y
注意事項:
繪製直方圖時,必須留意組距(bins)數的多寡,這將影響觀察的判斷。
同樣值得注意的是 Y 軸的調整,以便得到較好的觀察視野。當貼上 PDF 線圖時,直方圖必須採用相對頻率。
練習:抽樣分配 Sampling Distribution

利用隨機樣本並繪製直方圖(含真實 PDF 圖)與 ECDF 圖(含真實 CDF 圖)來證實 

注意事項:
分別選擇樣本數
,並觀察樣本數多寡的影響。
練習:抽樣分配 Sampling Distribution



這是 F 分配,自由度 


注意事項:
分別選擇樣本數
練習:抽樣分配之中央極限定理 Sampling Distribution for Central Limit Theorem (CLT)
中央極限定理之簡易描述:
Let
Let
As
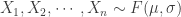

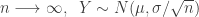
模擬實驗設定:
令隨機樣本
來自
,
令樣本數為
。
令每次實驗共抽樣
次,即得到
個平均數


實驗結果觀察:(for each 
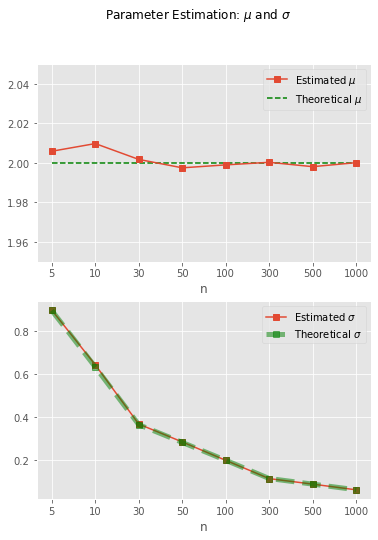
繪製
的直方圖,並與定理期望的常態分配
的 PDF 線對照,譬如下圖左的直方圖來自
,
, 及
。
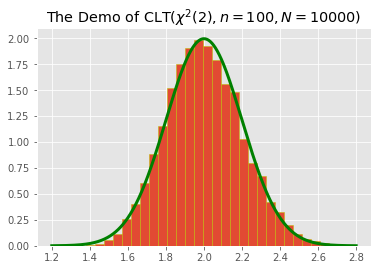
計算
與樣本數
值(譬如
)。 同樣地,也計算
與樣本數的折線圖,如下圖右下。
繪製下圖右的兩張圖時,必須謹慎選擇 Y 軸的範圍與 X 軸的 xticklabels,方能呈現好看的圖。這是從事統計計算必須具備的能力。不只是把圖畫出來而已。簡單的作法是將 x 軸的數值轉換為文字,以避免數字的大小影響版面配置,譬如 plt.plot(n.astype(str), mu, marker=”s”),其中 n 代表 [5, 10, 30, 50, 100, 300, 500, 1000] 的向量,mu 代表根據每個 n 值所估計出來的平均數。
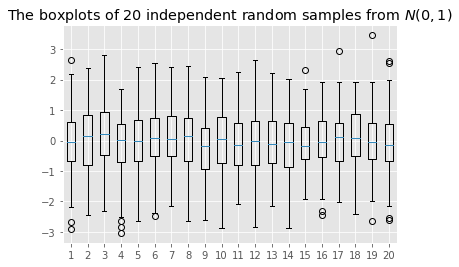
範例 5:多組樣本的盒鬚圖 Boxplot for multiple data sets
盒鬚圖經常被用來呈現多組樣本的敘述統計量之間的差異。繪製如下圖的
import matplotlib.pyplot as plt
from scipy.stats import norm
n, N = 100, 20
X = norm.rvs(size=(n, N))
plt.boxplot(X)
plt.title('The boxplots of {} independent random samples from $N(0,1)$'.format(n))
plt.show()
習題:
選擇三個曾經學過的抽樣分配,透過隨機抽樣的模擬方式,與理論互相驗證。其中樣本數、模擬次數與繪製何種圖形,請自行決定。
給定四個數字 (2, 4, 9, 12)。從這四個數字中隨機抽取四個數字(取後放回)並計算其平均數。假設隨機變數
Hint: 取後放回的抽樣方式,可以使用 numpy 的 random.choice。而從重複的數字中取出不重複的部分,可以使用 numpy 的 unique。(本題出自 Statistical Inference by G. Casella & R.L. Berger)
專題:
令
代表來自標準常態
表示為
,
其中
為偏態係數(skewness)的估計值。請利用蒙地卡羅模擬(Monte Carlo Simulation)驗證統計量
樣本數
。
針對每個樣本數
繪製
與
時,統計量
同上,但令統計量為
,
其中
為峰態係數(Kurtosis)的估計值。同樣利用蒙地卡羅模擬,驗證統計量
服從標準常態
同上,但統計量為
,
同樣利用上述的蒙地卡羅模擬,驗證統計量
服從卡方分配
。
