
Lesson 8: 雙變量函數的繪圖 & 多變量函數的參數估計與極值計算
Objective
- 學習繪製雙變量函數的立體圖。
- 繪製雙變量函數的等高線圖。
- 計算限制式與非限制式多變量函數的極值。
- 學習多變量模擬資料的生成。
- 解決混合常態與混合貝他分配的參數估計問題(normal and
mixture data)。
Prerequisite
- 單變量函數的繪製與極值計算。
範例 1:繪製 Mesh 與 Surface 立體圖
繪製函數
的立體網格圖(mesh(wireframe), surface)。
計算函數
的最小值。
注意事項:
學習如何寫出多變量函數的指令。
第一張圖稱為 mesh(wireframe) 圖,第二張稱為 surface 圖。
在指令 plot_wireframe 內的參數 “rstride” 與 “cstride” 用來控制網格的列與欄的密度,數值越小代表密度越高。讀者宜自行調整並觀察結果。
立體圖的觀賞角度有二: 仰角(elevation) 與水平角度(azimuth). 一般而言,立體圖的兩個角度都必須經過調整,才能看到最好、最適合或最想呈現的部分,俟調整好後,紀錄兩個角度並放入指令參數中(view_init),以便讓每次的執行都能顯示出該觀賞角度。值得注意的是,在 jupyter notebook 的環境下,無法手動調整觀賞角度,必須在 python 環境才可以(py 檔)。
Mesh 圖以網格線呈現立體模樣,而 surface 則是以塗滿色彩取代格線的立體圖並搭配色彩拼盤 cmap. 請參考 matplotlib 手冊中關於 color map 的使用,譬如 plt.cm.bone。
surface 以色彩表達立體模樣,因此經常搭配一條 color bar 來表示高度數值。
import numpy as np
import matplotlib.pyplot as plt
f = lambda x : x[0] * np.exp(-x[0]**2 - x[1]**2)
x = np.linspace(-2, 2, 100)
y = np.linspace(-2, 3, 100)
X, Y = np.meshgrid(x, y) # mesh grid matric
Z = f([X, Y])
# for wireframe, control the wire density by rstride and cstride
fig = plt.figure(figsize=(9, 6))
ax = plt.axes(projection = '3d')
ax.plot_wireframe(X, Y, Z, color ='blue',
alpha=0.3, rstride = 1, cstride = 1)
ax.set_xlabel('X'), ax.set_ylabel('Y')
ax.set_zlabel('f(X,Y)')
ax.view_init(10, -60) #(elev=-165, azim=60)
plt.title('Wireframe (Mesh) Plot')
plt.show()
# for surface 3D plot
fig = plt.figure(figsize=(9, 6))
ax = plt.axes(projection = '3d')
surf = ax.plot_surface(X, Y, Z, color = 'r', \
rstride=4, cstride=4, alpha =0.6, cmap='ocean') # cmap = plt.cm.bone
# cmap = plt.cm.bone
fig.colorbar(surf, ax=ax, shrink=0.5, aspect=10) # aspect = length/width ratio
ax.view_init(10, -60) #(elev=-165, azim=60)
ax.set_xlabel('X'), ax.set_ylabel('Y')
plt.title('Surface Plot')
plt.show()


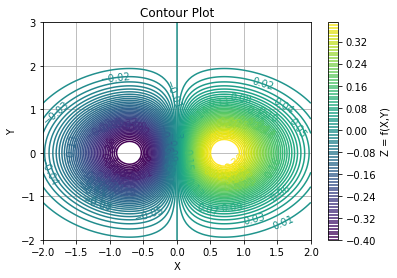
範例 2:等高線圖 Contour plot
延續上個範例的函數, 繪製等高線圖。
注意事項:
等高線的線條代表某個函數值。而函數值大小通常以線條顏色表達。
繪製等高線必須決定等高線的數量或等高線的高度。下列程式碼分別展示這兩種做法。
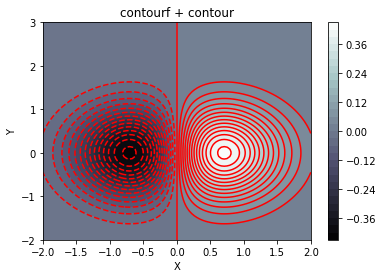
除了以線條來展現函數值的大小,指令 contourf 則是使用塗滿區域顏色的方式表達數值大小。
下列程式碼也示範了 colorbar 的進一步技巧。.
... continued with the previous codes ...
# To draw a contour plot
levels = np.arange(-0.4, 0.4, 0.01) # levels of contour lines
contours = plt.contour(X, Y, Z, levels=levels) # check dir(contours)
# add function value on each line
plt.clabel(contours, inline = 0, fontsize = 10) # inline =1 or 0
cbar = plt.colorbar(contours)
plt.xlabel('X'), plt.ylabel('Y')
cbar.ax.set_ylabel('Z = f(X,Y)') # set colorbar label
# cbar.add_lines(contours) # add contour line levels to the colorbar
plt.title('Contour Plot')
plt.grid(True)
plt.show()
... continued with the previous codes ...
# draw a contour plot with contourf
C1 = plt.contourf(X, Y, Z, 30, \
cmap = plt.cm.bone)
C2 = plt.contour(C1, levels = C1.levels, \
colors = 'r') # check dir(contours)
plt.colorbar(C1)
plt.xlabel('X'), plt.ylabel('Y')
plt.title('contourf + contour')
plt.show()
範例 3:無限制式條件下的多變量函數最小值 The unconstraint minimization
計算上一個範例中的多變量函數之最小值,即 
Note:
指令 scipy.optimize.fmin 用來計算多變量函數的最小值(區域最小值)。
scipy.optimize.fmin 指令包含許多輸入參數,做為演算法收斂的依據,譬如 “maxiter = 1000” 定義了演算法的最大迴圈數為 1000; “maxfun = 1000” 則是限制函數計算的次數為 1000 次,限制次數的原因往往是該函數的計算過於耗時,無法承受太多次,只好停止演算,接受尚未真正收斂的結果; “disp = False” 表示不顯示執行結果的細節; “full_output = True” 會將最最後的最佳函數值輸出。 其他常用的重要參數還有 “xtol” 與 “ftol”,分別代表演算法執行過程中,當估計參數 x 的變化小於 “xtol” 與目標函數的變化小於 “ftol”,則停止演算法。 為方便這些參數的設定與使用,可以參考 dictionary list 的做法,請參考下列程式碼的最後兩行。
讀者可以列印出輸出變數 “OptVal” 看看裡面有些甚麼。
指令 scipy.optimize.fmin 使用 downhill simplex 演算法,這個演算法不需要函數的任何導函數,因此適用於複雜,不易計算導函數的函數。
import numpy as np
import scipy.optimize as opt
f = lambda x : x[0] * np.exp(-x[0]**2 - x[1]**2)
OptVal = opt.fmin(func = f, x0 = [0, -1], maxiter = 1e3, maxfun = 1e3, disp = False, full_output = True)
print('The minimum occurrs at x = {:.4f}, y = {:.4f}'.format(OptVal[0][0], OptVal[0][1]))
print('The function vaule is {:.4f}'.format(OptVal[1]))
# Use a dictionary to express algorithmic parameters
opts = dict(disp = 1, xtol = 1e-6, ftol = 1e-6, maxfun = 1e4, maxiter = 1e4, full_output = True)
OptVal = opt.fmin(func = f, x0=[0, 0], **opts)
練習:
從上述的範例,在函數的等高線圖上,標記區域最小值與最大值。
練習:
函數 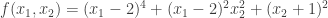
繪製立體圖(wireframe)與等高線圖(contour)。
計算
.
練習:
著名的 Rosenbrock’s banana 測試函數

繪製立體圖(wireframe)與等高線圖(contour)。
計算
.
範例 3:限制式條件下的最小值問題 The constraint minimization
求解下列限制式條件的最小值

其中 
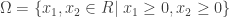
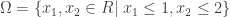



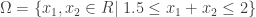
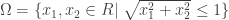

注意事項:
限制式條件包括線性與非線性的不等式(inequalities).
限制式條件的最小值問題更常見於一般應用(較之於非限制條件)。
在本範例中,使用 scipy.optimize.minimize 計算限制式條件的最小值。
本題的非限制條件版,已在前面計算過,看看在限制式與非限制的條件下所得到的答案合不合理。
下列被註解的程式碼,建議不同的做法,讀者可以試試。
指令 minimize 因應不同的限制條件,使用兩個參數 bounds 或 constraints 放入限制條件。一般而言,簡單的針對各變量的範圍限制,採 bounds,如果限制條件牽涉變數間的函數關係或非線性關係,則採用 constraints。下列程式碼為方便起見,同時置入這兩個參數,因此當指用到 constraints 時,會將 bounds 設為 [(-np.inf, np.inf)),(-np.inf, np.inf)] 即
,
。
指令 minimize 也能用在非限制式條件的問題上,參考手冊上關於 minimize 與 fmin 之不同( scipy.optimize)。
import scipy.optimize as opt
import numpy as np
f = lambda x: (x[0] - 2)**4 + (x[0] - 2)**2*x[1]**2 + (x[1]+1)**2
opts = dict(disp = True, maxiter=1e4)
# 1
cons = [{'type': 'ineq', 'fun': lambda x: x[0]}, {'type': 'ineq', 'fun': lambda x: x[1]}]
bnds = [(-np.inf, np.inf)),(-np.inf, np.inf)]
# 2: approach 1
# cons = []
# bnds = [(None, 1), (None,2)]
# 2: approach 2
# cons = [{'type': 'ineq', 'fun': lambda x: 1 - x[0]}, {'type': 'ineq', 'fun': lambda x: 2 - x[1]}]
# bnds = bnds = [(-np.inf, np.inf)),(-np.inf, np.inf)]
# 3
# cons = []
# bnds = [(0, 1), (0, 2)]
# 4
# cons = []
# bnds = [(0, np.inf), (-np.inf, 2)]
# 5
# cons = {'type': 'ineq', 'fun': lambda x: -x[0] - x[1] + 0.9}
# bnds = bnds = [(-np.inf, np.inf)),(-np.inf, np.inf)]
# 6: approach 1
# cons = [{'type': 'ineq', 'fun': lambda x:
# x[0] + x[1] - 1.5},
# {'type': 'ineq', 'fun': lambda x:
# -x[0] - x[1] + 2}]
# bnds = bnds = [(-np.inf, np.inf)),(-np.inf, np.inf)]
# 6: approach 2
# A = [[1, 1], [-1, -1]]
# b = [-1.5, 2]
# cons = {'type': 'ineq', 'fun': lambda x:
# A @ x + b}
# bnds = bnds = [(-np.inf, np.inf)),(-np.inf, np.inf)]
# 6: approach 3
# A = [1, 1]
# lb, ub = 1.5, 2
# cons = opt.LinearConstraint(A, lb, ub)
# bnds = bnds = [(-np.inf, np.inf)),(-np.inf, np.inf)]
# 7: approach 1
# cons = {'type': 'ineq', 'fun': lambda x:
# 1 - np.sqrt(x[0]**2 + x[1]**2) }
# 7: approach 2
# con = lambda x: np.sqrt(x[0]**2 + x[1]**2)
# lb, ub = 0, 1
# cons = opt.NonlinearConstraint(con, lb, ub)
# bnds = bnds = [(-np.inf, np.inf)),(-np.inf, np.inf)]
# 8:
# cons = [{'type': 'ineq', 'fun': lambda x:
# 1 - np.sqrt(x[0]**2 + x[1]**2)},
# {'type': 'ineq', 'fun': lambda x:
# x[0] * x[1]}]
# bnds = bnds = [(-np.inf, np.inf)),(-np.inf, np.inf)]
res = opt.minimize(f, x0=[0, 0],
bounds = bnds,
constraints = cons,
options = opts,
tol = 1e-8)
# print(res)
print('x1 = {:.4f}, x2 = {:.4f}'.format(res.x[0], res.x[1]))
print('function value is {:.4f}'.format(res.fun))
範例 4:混合貝他分配的參數估計 The
給定 1000 筆資料,其直方圖如下所示。已知這些資料來自兩個貝他(
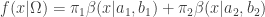
其中 

目標函數寫為
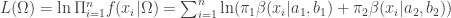
依下列步驟模擬樣本的生成與參數估計
-
設定參數條件(scenario),譬如,
, 樣本數
。
-
根據上述的參數條件,繪製混合貝他分配的 PDF 圖,看看母體的長相。
-
根據上述參數條件,生成隨機樣本。
-
繪製隨機樣本的直方圖,如下圖。
-
計算 MLE 的最大值問題(限制式條件)。
-
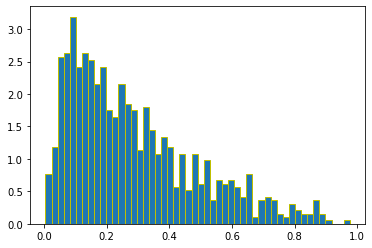
使用估計後的參數值,繪製混合 PDF 圖,並與樣本直方圖、理論的混合 PDF 圖並陳,如右下圖。
import numpy as np
import scipy.optimize as opt
import matplotlib.pyplot as plt
from scipy.stats import beta, binom
# set up the parameters --------------
pi1, a1, b1, a2, b2 = 0.7, 2, 9, 3, 3
# draw the mixture pdf ---------------
f = lambda x: pi1 * beta.pdf(x, a1, b1) + (1-pi1) * beta.pdf(x, a2, b2)
x = np.linspace(0, 1, 1000)
plt.plot(x, f(x), color = 'r', linewidth = 3, label = 'True mixture')
# generate the simulated sample -------
n = 1000
n1 = binom.rvs(n, pi1)
n2 = n - n1
sample = np.r_[beta.rvs(a1, b1, size = n1),
beta.rvs(a2, b2, size = n2)]
# plot histogram ------------------------
plt.hist(sample, 50, edgecolor = 'y', density = True)
# max mle (min -mle) --------------------
L = lambda x : -np.sum(np.log(x[0] * beta.pdf(sample, x[1], x[2]) + (1 - x[0]) * beta.pdf(sample, x[3], x[4])))
# the constraints, bounds and options
cons = []
bnds = [(0, 1), (0, np.inf), (0, np.inf), (0, np.inf), (0, np.inf)]
opts = dict(disp = True, maxiter = 1e4)
x0 = [0.5, 1, 10, 5, 5] # initial guess
res = opt.minimize(L, x0 = x0,
bounds = bnds,
constraints = cons,
options = opts,
tol = 1e-8)
# show the results and comapre to res.fun with population parameters
print(res)
# print(L([pi1, a1, b1, a2, b2])) # the function value of the initial guess
# plot the estimated mixture pdf
f_hat = lambda x: res.x[0] * beta.pdf(x, res.x[1], res.x[2]) + (1-res.x[0]) * beta.pdf(x, res.x[3], res.x[4])
plt.plot(x, f_hat(x), color = 'k', linestyle = '--', \
linewidth = 3, label = 'Estimated mixture')
plt.legend()
plt.show()
注意事項:
-
這是限制式條件的最大值問題,限制式是:
,
.
指令 minimize 內建的演算法是 L-BFGS-B.
練習:混合貝他分配參數估計(續)
重作上述的貝他混合分配的參數估計,但是重新設定實驗參數,譬如,觀察樣本數
的估計精準度。
改變混合比例
, 及兩個貝他分貝的參數
,
。
針對每一組參數設定,重複生成模擬資料並進行估計,共
次,最後取平均並與真實參數值比較。
練習:混合貝他分配參數估計的評估
MLE 估計的表現可以用下列的方式來評估:其中 

Mean: 理論值:
, 實驗值:
,如圖一所示。
Bias: 理論值:
, 實驗值:
,如圖二所示。
Variance: 理論值:
, 實驗值:
.
Mean Squared Error (MSE): 理論值:
, 實驗值:
. 另一常見的誤差表達方式為 Root Mean Squared Error (RMSE),實驗值取
,讓誤差值與估計值在相同的”水平”。如圖三所示。
Consistency: 評估方式
Asymptotic Normality: 評估方式: Check if the sampling distribution of the estimator
becomes normal as the sample size increases.

本題共有 5 個參數需要估計,因此以上的評估必須針對每個參數進行,以便觀察那些參數的估計較好,那些較差,如下圖展示在不同樣本數下 5 個參數在 10000 次模擬估計值下的平均數 Mean, 偏差 Bias 及 誤差平方的均方根 RMSE,其中當樣本數 



習題 1:混合常態參數估計 Normal Mixture
前面的範例應用最大概似估計法估計混合貝他(
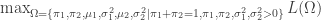
其中對數聯合概似函數為



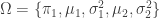
自行設定資料生成的參數
較接近(視覺上好像只有一組),另一組分開較遠些(視覺上看出兩個常態混合)。以下圖一可做為參考。
總樣本數
。藉以評估樣本數大小對估計值的影響。
繪製執行結果,含資料的直方圖、真實的混合常態 PDF 與估計的混合常態 PDF。因每次執行的結果會因為樣本資料之不同而不同,選擇其中某一次即可,如圖二。
(Optional)混合常態的估計問題已經有一段歷史了,不難想像早已被寫成套件,譬如 sklearn.mixture.GaussianMixture。使用方式請自行參照使用手冊。另外,安裝方式稍不同於一般套件,Windows 版本為:pip install -U scikit-learn。請為圖二加上另一條由 sklearn.mixture.GaussianMixture 估計的混合常態 PDF 函數,如圖三。該套件使用著名的 EM 演算法估計相關參數。圖四則列出使用 optimize.minimize 與 GaussianMixture 估計的參數值。
注意事項:
多變量的最小值問題常常對於初始值的選擇很敏感,因此讀者不妨多嘗試不同的初始值,看看結果如何。當針對某些資料得到不好的估計值時,可以換初始值,或是乾脆在執行一次(即換另一組資料)。
圖一展示 6 張 subplots 圖,下列程式片段提供簡單迅速的呈現方式。
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-3*np.pi, 3*np.pi, 100)
y = np.sin(x)
fig, axes = plt.subplots(2, 3, figsize=(8, 6))
for i, ax in enumerate(axes.flat):
ax.plot(x, y)
ax.set_title('i={}'.format(i))
plt.show()
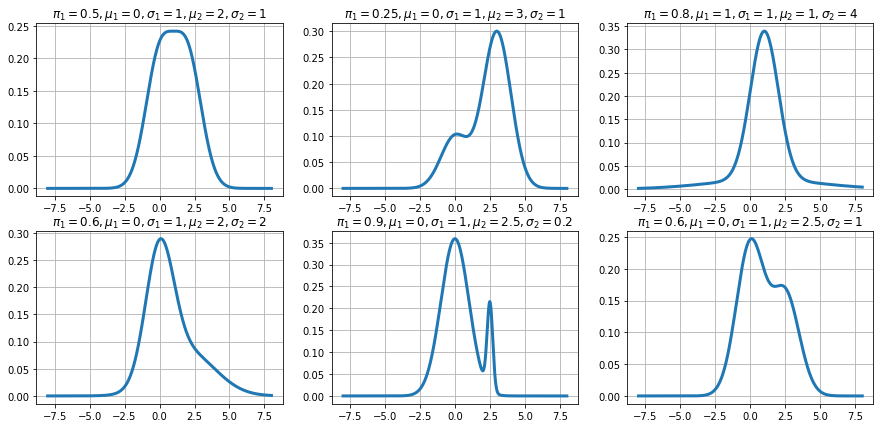


sklearn.mixture 使用注意事項
sklearn 是淺度機器學習的套件,其中的 sklearn.mixture 提供單變量與多變量混合常態的參數估計。其中符合本題單變量混合常態的使用方式如下程式碼。
Python 機器學習(淺度或深度)的模式大致相同;第一、先設定學習模式,如下程式碼之 gmm=GaussianMixture(…),從此 gmm 代表這個學習模型的物件,所有後續的操作與操作後的結果都放於此;第二、匯入資料開始學習,如 gmm.fit(…),fit 是凝合的意思,也是模型訓練或參數估計的意思。就混合常態的估計而言,最後的結果就是混合常態中多個常態函數的配置比例(gmm.weights_)、所有常態的平均數(gmm.means_)與變異數(多變量下的共變異矩陣)(gmm.covariances_)。
執行 GaussianMixture(…) 分離出兩個以上的常態分配,有一個小地方必須謹慎對待:執行結果放在 gmm.weights_、gmm.means、mm.covariances 的估計值並沒有一定的順序,也就是函數所寫的
可能以不同的順序放在 gmm.weights_,而且隨樣本而變。因此,當執行蒙地卡羅實驗時,必須對所有估計值進行排列,方能進行後續的評估。另一個解決方案是以人為方式介入初始值的選擇,使得演算法「被迫」按初始值的順序排列估計結果。譬如在 GaussianMixture(…, weights_init=[pi1, 1-pi1], means_init=np.array([mu1, mu2]).reshape(2,1)),其中的 pi1, mu1, mu2 都是真實值。這個做法看起來很奇怪,但是用在蒙地卡羅實驗(預知真實值)還算可以。不過仍需小心觀察估計結果的排列。
GaussianMixture 的輸入資料為矩陣型態,大小為 n x p,n 為樣本數,p 為變數個數。本題為單變量函數,資料型態為 n x 1,因此必須加上 sample.reshape(-1, 1)。
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=2, covariance_type='full',\
verbose = 0, max_iter = 1000, tol = 1e-6)
gmm.fit(sample.reshape(-1, 1)) # sample is the normal mixture data as a column vector
# gmm.weights_
# gmm.means_
# gmm.covariances_
習題 2:限制式條件的最大值問題 Constraint optimization
計算下列最大概似估計 MLE 問題的參數 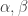

其中的聯合概似函數為

where 

變數 
建議依下列程序,逐步進行:
(不熟悉的部分,再往前面的範例或章節找到可供參考的程式片段)
-
先下載資料檔,取出資料並觀察資料的樣子。
目標函數
需要進一步推導到比較適合的樣子,也就是將
透過
換成
。並不是連乘的
或
利用推導到精簡的目標函數,繪製立體圖與等高線圖。繪圖時,需要摸索參數的範圍,找到最佳的觀察位置。畫得好,隱約可以看出最大值的位置(如下圖)。
接著開始部署 minimize 的各項停止條件及計算。有了等高線圖的幫助,通常答案已經呼之欲出,計算的結果只是得到一組更明確的數據。如圖中紅色的 X。
請留意概似函數中的
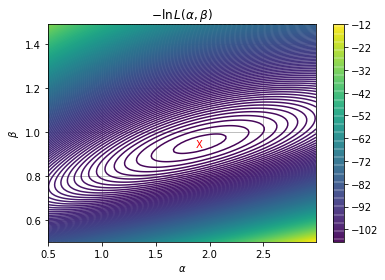
習題 3:限制式條件的最小值問題
假設兩獨立變數 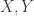


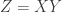

我們想以另一個貝他分配 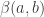
假設 

提示:
本題題意暗示
的長相,如下圖的
。本題的意思便是要找一個最接近
,確實與
皆為貝他分配,有利後續更多組合的分配配適。
當匿名函數比較複雜時,可以搭配副程式將複雜的部分拉到副程式去做。
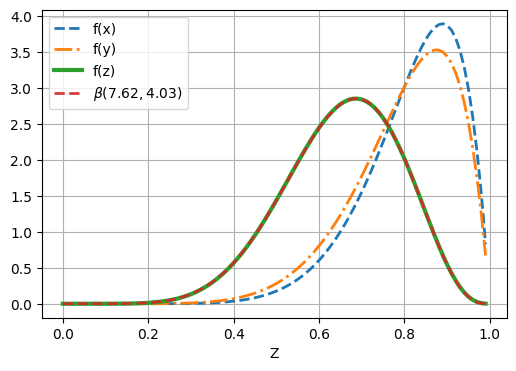
這個目標函數牽涉到內外層兩個積分,使得程式的撰寫有點彆扭。因此建議先畫出
接著試著寫出目標函數
。在進行下一步計算最小值之前,先測試函數是否寫對了(或至少能產生函數值),譬如帶入
.
minimize 指令內建許多演算法(BFGS, Nelder-Mead simplex, Newton Conjugate Gradient, COBYLA or SLSQP,…etc.),各有擅長應對的函數(有些適合處理 constraint,有些不適合)。再試著不同的演算法,譬如 method = ‘L-BFGS-B’,看看哪個比較快。
本題來自可靠度分析的研究,利用元件可靠度的 beta 分配建立整個系統系統的可靠度分配。譬如,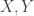

練習:串聯元件的可靠度模擬:以數值方式估計貝他參數
前述新變數 

此外,本練習將使用模擬的方式產生變數
模擬生成
,其中
。
根據
樣本進行 MLE 估計。可以採用
本節講義的限制式雙變量函數的最小值估計方法,譬如採 scipy.optimize.minimize,或是非限制式雙變量函數的最小值估計方法 scipy.optimize.fmin。當然必須寫一個目標函數的副程式。
比較簡便的方式是採 scipy.stats 的 beta.fit 函數進行估計,其中的 method=’MLE’,譬如
a, b, loc, scale = beta.fit(data, method=’MLE’, floc=0, fscale=1)。
其實 method=’MLE’ 也是 default 值,不指定也可以。
同 2. 但使用 Method of Moments 估計參數
:
直接計算:
比較簡便的方式是採 scipy.stats 的 beta.fit 函數進行估計,其中的 method=’MM’,譬如
a, b, loc, scale = beta.fit(data, method=’MM’, floc=0, fscale=1)。

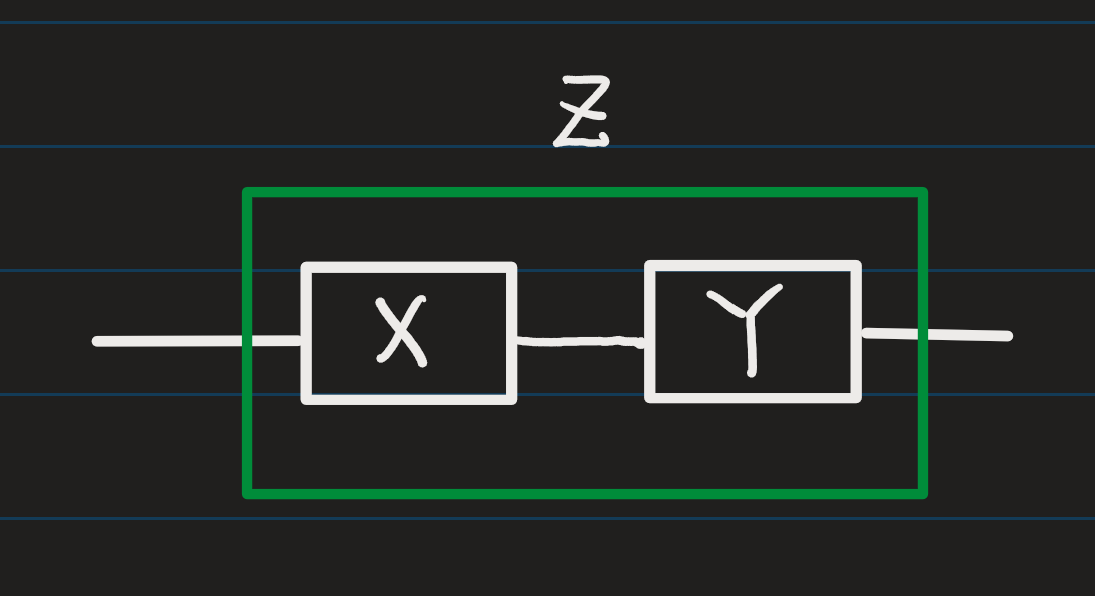

練習:並聯元件的可靠度模擬:以數值方式估計貝他參數
前述的串聯不可避免地造成整體可靠度下降,若更多的元件加入串聯勢必一再地拉低可靠度,為維持一定的可靠度,最直覺的方式是提高個別元件的可靠度,此時可以利用相同元件並聯的方式以提高該元件的可靠度。
若視 



