專題
程式設計者的養成必須假以實戰,不能光寫或模仿一些小程式片段。本章設計幾個簡單但完整的專題,從問題出發,引導讀者從程式的角度來解決問題。需要用到的程式技巧已經在前面的章節介紹過,一方面複習學過的技巧與觀念,一方面逐漸熟悉解決問題的切入點與最終結果的表達(Presentation)。建議讀者看完題目後,先思考如何下手,甚至直接動手寫,以收實戰訓練之效。
專題 1:常態分配的平均數 

令 


假設
),
其中代表常態分配
的機率密度函數(PDF)。
自常態分配
。
計算(定義)聯合概似函數(輸入為:所有樣本、
。
固定
,如圖一。
從
,請在這個位置做個記號,譬如打個 X 或畫上一條垂直線,方便觀察。
重複執行上述步驟,觀察最大概似函數估計值
改變樣本數
,重複上述步驟,持續觀察
計算聯合概似函數
或
By formula:
.
By grid search.
By various algorithms, e.g. scipy.optimize.minimize_scalar().
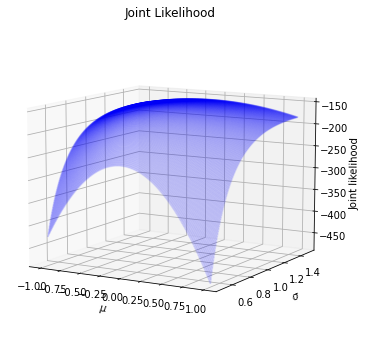
假設
皆未知,繪製聯合概似函數
Compute
.
繪製等高線圖 Contour plot。
繪製立體圖 wireframe, surface plots。
聯合概似函數
計算限制式條件下的多變量函數最小值(Constraint minimization problem), i.e.
或
.




專題 2:
單位圓的面積是 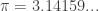
在單位圓周圍的外切正方形內,均勻的投擲
假設落在單位圓內的數量為
,則依據面積比(單位圓 vs. 正方形面積)與落點分佈比的關係
得出估計值
。
顯然,當
將愈接近
接著,選擇一個適當的、夠大的
次估計,結果表示為
。計算這

專題 3:雙樣本 T 檢定的 p-value 分佈
統計應用上經常需要檢定兩組資料的母體(來源)平均數是否相等,一般稱為雙樣本 T 檢定(Two-Sample T test),寫成


檢定統計量為:

這是一般統計教科書的經典內容。這裡透過簡單的程式做實驗來理解其中的概念。以下是實驗的想法:
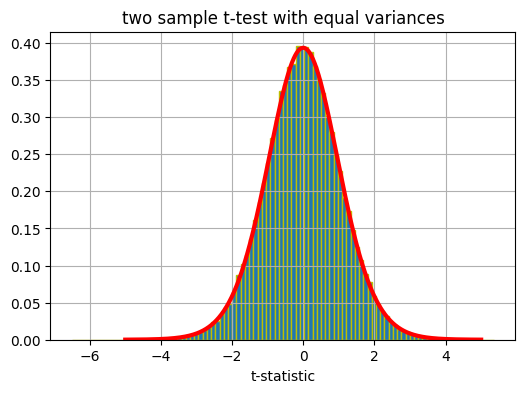
上述的檢定統計量
服從 T 分配,因此這類的檢定稱為「雙(獨立)樣本 T 檢定」。首先,做個實驗來驗證這個抽樣分配確實服從 T 分配(自由度 df = …),即當兩組樣本來自
的假設,譬如
,樣本數分別為
(自訂);執行抽樣共
假設兩組資料都來自標準常態母體
。 對這兩組資料進行雙樣本 T 檢定,將得到一個 p-value。想透過實驗知道這個 p-value 的分佈,換句話說,如果將這個 p-value 當作一個隨機變數,它的分配會是什麼?先猜猜看,再來寫程式做實驗。實驗設定
。
承上,但假設兩組資料分別來自不同的常態分配
(如圖二)。在兩母體平均數不同的情況下,生成的資料在雙樣本 T 檢定下,p-value 將呈現什麼樣的分佈?
承上,繼續改善程式以便觀察當兩常態母體的平均數差距較大時(如圖二中、右),所生成的樣本在雙樣本 T 檢定下,p-value 分佈有什麼變化?
兩獨立樣本的 T 檢定可使用 scipy.stats.ttest_ind(x1, x2)。注意,該指令除了輸入兩個樣本資料外,尚有其他選項,譬如 equal_var=True 表示假設兩樣本的變數數相等,此時自由度會是 n1+n2-2,相關細節可以查詢使用手冊。
假設兩樣本分別來自常態
,計算指令 scipy.stats.ttest_ind 的檢定力。
同上,當樣本數
時,scipy.stats.ttest_ind 的檢定力分別是多少,繪製一張圖來展現樣本數與檢定力的關係,如圖三。

專題 4:以蒙地卡羅實驗驗證 J-B 檢定統計量
令
代表來自標準常態
表示為
,
其中
為偏態係數(skewness)的估計值(參考指令 scipy.stats.skew)。請利用蒙地卡羅模擬(Monte Carlo Simulation)驗證統計量
樣本數
。
針對每個樣本數
。
繪製
與
時,統計量
同上,但令統計量為
,
其中
為峰態係數(Kurtosis)的估計值(參考指令 scipy.stats.kurtosis)。同樣利用蒙地卡羅模擬,驗證統計量
服從標準常態
同上,但統計量為
,
同樣利用上述的蒙地卡羅模擬,驗證統計量
服從卡方分配
。
將上述驗證程式改寫為一個副程式,假設取名為 stats, p_value = JB_test(x),輸入參數 x 代表欲檢定是否為常態的一組資料。 輸出兩個結果,stats 為
接著檢驗檢定統計量
從下列的分配母體中抽樣:
。
抽樣數
。
實驗次數
。
型一誤
。
對每個分配母體與樣本數,分別計算檢定力:
,其中
資料來自常態;
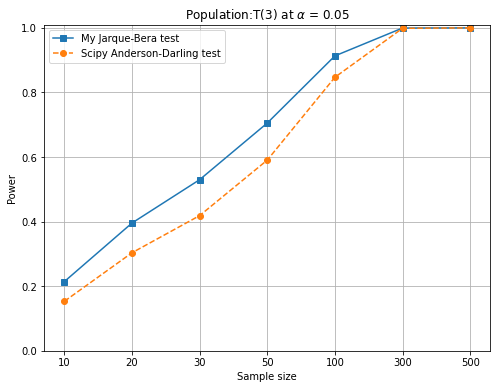
資料來自其他分配。 最後針對每個母體,繪製如下圖的 Power vs. sample size。觀察檢定力受樣本數與母體來源(與常態的相似度)的影響。其中 Y 軸必須選擇合適的範圍,方能呈現出清楚的 power 值。
其實,當
來自常態時(也就是資料來自
,即
,如下圖左。因此,當檢定統計量無法維持既定的顯著水準時,後續的檢定力也不用做了。因為檢定統計量是根據
一般而言,檢定力會隨著樣本數增加而變大,亦即,樣本數大有利於辨認資料的「真偽」。
上述的分配中,偏斜常態(skewed normal)可以從 scipy.stats.skewnorm 生成,該指令的第一個參數
的正負決定了右偏還是左偏,
 ,檢定力也稱「顯著水準」,理論上必須維持在 值
,檢定力也稱「顯著水準」,理論上必須維持在 值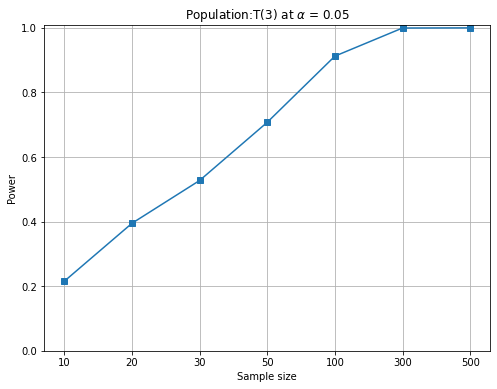 ,檢定力隨著樣本數增加而變大
,檢定力隨著樣本數增加而變大上述的 JB 統計量或稱 JB test 可以拿來與其他常態檢定的產品比試一下。譬如,scipy.stats 也提供了 Jarque–Bera test( jarque_bera), D’Agostino and Pearson’s (normaltest), Kolmogorov-Smirnov test(kstest), Shapiro-Wilk test(shapiro) 與 Anderson-Darling test(anderson) 等常態檢定的指令。下圖以 Anderson-Darling test 與本專題的 JB test 比較(蒙地卡羅實驗 5 萬次),左圖為顯著水準的維持,右圖為對 T(3) 分配的檢定力。從左圖看出 scipy 的 anderson 指令在小樣本時,型一誤的維持較差,即便樣本數升高也比 JB test 差。另,右圖在對 T(3) 的檢定力也比 JB test 差,直到樣本數上升到 300 才趕上(本實驗沒有嘗試樣本數介於 100~300 之間)。雖然從下圖的比較中,JB test 優於 scipy 的 anderson,但這不意味著 JB test 比 Anderson-Darling test 好,很有可能是scipy 的這支 anderson 程式並沒有寫好。何況本專題的 JB test 在樣本數小於 2000 時,統計量並不滿足該有的卡方分配。讀者可以試試 scipy 的其他指令。
在 scipy 1.14.1 版,以上這幾個指令除了 anderson 外,都能多時對多組資料進行檢定統計量與 p-val 的計算。另,使用 anderson 指令除須掛上迴圈才能做多組資料的檢定外,這個指令也不生成 p value,而是採計算出來的 statistic 與內含的 critical value 做比較,詳細作法請讀者自己細細研究。